
The overall goal of this series is to explore a number of machine learning algorithms utilizing natural language processing (NLP) to classify the sentiment in a set of IMDB movie reviews.
The specific goals of this particular post include:
- Create a set of document vectors from the IMDb movie review text utilizing Doc2Vec
- Tune and train a number of Doc2Vec models on the movie review corpus
- Run the models from the first write-up against the Doc2Vec feature set outputs
- Determine if utilizing Doc2Vec improves our ability to correctly classify movie review sentiment
Links
- This series of write-ups is inspired by the Kaggle Bag of Words Meets Bags of Popcorn competition.
- Dataset source: IMDB Movie Reviews
- You can find the source Jupyter Notebook on GitHub here.
Previous
Previous entries in this series:
- IMDB Movie Review Sentiment Classification - Part One
- Creating the baseline model
- IMDB Movie Review Sentiment Classification - Part Two
- Utilizing a sparse feature set
- IMDB Movie Review Sentiment Classification - Part Three
- Utilizing world embeddings and K-nearest neighbors analysis
Process
Previously covered here.
Configure notebook, import libraries, and import dataset
Import libraries
%matplotlib inline
%load_ext autoreload
%autoreload 2
import warnings
warnings.filterwarnings('ignore')
import os
import re
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import smart_open
from random import shuffle
import pandas as pd
from pandas import set_option
from tqdm import tqdm
tqdm.pandas(desc="progress-bar")
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# http://www.nltk.org/index.html
# pip install nltk
import nltk
from nltk.corpus import stopwords
# Creating function implementing punkt tokenizer for sentence splitting
import nltk.data
# Only need this the first time...
# nltk.download('punkt')
# https://www.crummy.com/software/BeautifulSoup/bs4/doc/
# pip install BeautifulSoup4
from bs4 import BeautifulSoup
# https://pypi.org/project/gensim/
# pip install gensim
import gensim.models.doc2vec
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level = logging.INFO)
import multiprocessing
cores = multiprocessing.cpu_count()
assert(gensim.models.doc2vec.FAST_VERSION > -1, "Going to be slow!")
Define global variables
seed = 10
np.random.seed(seed)
# Opens a GUI that allows us to download the NLTK data
# nltk.download()
dataPath = os.path.join('.', 'datasets', 'imdb_movie_reviews')
labeledTrainData = os.path.join(dataPath, 'labeledTrainData.tsv')
Helper Functions
The following function trains the “standard” set of Scikit-learn models we’ve been evaluating and returns the results. This should reduce the verbosity of the write-up below.
def trainModels(xTrain, yTrain, modelsToRun = ['LR', 'LDA', 'SVM']):
# Init vars
folds = 10
seed = 10
models = []
results = {}
# Use accuracy since this is a classification
score = 'accuracy'
# Instantiate model objects
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# Create a Pandas DF to hold all our spiffy results
_df = pd.DataFrame(columns = ['Model', 'Accuracy', 'StdDev'])
# Run the models
for modelName, model in models:
if (modelName in modelsToRun) or (modelsToRun == 'all'):
print("Training", modelName, "....")
# Implement K-fold cross validation where K = 10
kFold = KFold(n_splits = folds, random_state = seed)
results[modelName] = cross_val_score(model, xTrain, yTrain, cv = kFold, scoring = score)
_df.loc[len(_df)] = list([modelName, results[modelName].mean(), results[modelName].std()])
# Print results sorted by Mean desc, StdDev asc, Model asc
return(results, _df)
And another function to draw the whisker plots of model performance:
def makeWhisker(results):
figure = plt.figure(figsize = (8,6))
figure.suptitle("Model Results")
axis = figure.add_subplot(111)
plt.boxplot(results.values())
axis.set_xticklabels(results.keys())
plt.show()
Examine the data
Previously covered here.
Cleaning and preprocessing
Load labeled training data
(Previous process justification and methodology also previously covered here.)
We need to load the labeled training data exactly as we’ve done in previous write-ups:
# Pull in the labeled data
df = pd.read_csv(labeledTrainData, sep = '\t', header = 0, quoting = 3)
# Sanity check
print('df.shape :', df.shape)
df.shape : (25000, 3)
Write helper functions
Doc2Vec expects a list of TaggedDocument objects. The first argument of the TaggedDocument constructor is a contiguous list of words (which we’ll clean as usual), and the second argument is a unique tag. For example, here is what a sample TaggedDocument object looks like:
TaggedDocument(words=['with', 'all', 'this', 'stuff', 'going', 'down', 'at', 'the', 'moment', 'with', 'mj', 'i', 've', 'started', 'listening', 'to', 'his', ...... <SNIP>], tags=[0])
In order to facilitate this we’ll first write the “cleaner” function to process the review text:
Sentence cleaner
Take a given sentence and process/clean it (i.e. remove HTML and other cruft, lower case the text, etc.).
# Update stop word helper function to output a list of words
# Clean IMDB review text
def cleanReview(review, removeStopWords = False):
# Convert the stop words to a set
stopWords = set(stopwords.words("english"))
# Remove HTML
clean = BeautifulSoup(review)
# Remove non-alpha chars
clean = re.sub("[^a-zA-Z]", ' ', clean.get_text())
# Convert to lower case and "tokenize"
clean = clean.lower().split()
# Remove stop words
if removeStopWords:
clean = [x for x in clean if not x in stopWords]
# Return results
return clean
A quick examination of the output:
# Examine
cleanReview(df.iloc[25,2])[:12]
['looking',
'for',
'quo',
'vadis',
'at',
'my',
'local',
'video',
'store',
'i',
'found',
'this']
Create list of Doc2Vec TaggedDocument objects
Next we need to create a collection of TaggedDocument objects; one object for each review:
taggedDocs = []
for i, s in enumerate(df.iloc[:,2]):
clean = cleanReview(s)
taggedDocs.append(TaggedDocument(clean, [i]))
# Sanity check we have the same number of objects as reviews
len(taggedDocs)
25000
# Examine an example:
taggedDocs[0]
TaggedDocument(words=['with', 'all', 'this', 'stuff', 'going', 'down', 'at', 'the', 'moment', 'with', 'mj', 'i', 've', 'started', 'listening', 'to', 'his', 'music', 'watching', 'the', 'odd', 'documentary', 'here', 'and', 'there', 'watched', 'the', 'wiz', 'and', 'watched', 'moonwalker', 'again', 'maybe', 'i', 'just', 'want', 'to', 'get', 'a', 'certain', 'insight', 'into', 'this', 'guy', 'who', 'i', 'thought', 'was', 'really', 'cool', 'in', 'the', 'eighties', 'just', 'to', 'maybe', 'make', 'up', 'my', 'mind', 'whether', 'he', 'is', 'guilty', 'or', 'innocent', 'moonwalker', 'is', 'part', 'biography', 'part', 'feature', 'film', 'which', 'i', 'remember', 'going', 'to', 'see', 'at', 'the', 'cinema', 'when', 'it', 'was', 'originally', 'released', 'some', 'of', 'it', 'has', 'subtle', 'messages', 'about', 'mj', 's', 'feeling', 'towards', 'the', 'press', 'and', 'also', 'the', 'obvious', 'message', 'of', 'drugs', 'are', 'bad', 'm', 'kay', 'visually', 'impressive', 'but', 'of', 'course', 'this', 'is', 'all', 'about', 'michael', 'jackson', 'so', 'unless', 'you', 'remotely', 'like', 'mj', 'in', 'anyway', 'then', 'you', 'are', 'going', 'to', 'hate', 'this', 'and', 'find', 'it', 'boring', 'some', 'may', 'call', 'mj', 'an', 'egotist', 'for', 'consenting', 'to', 'the', 'making', 'of', 'this', 'movie', 'but', 'mj', 'and', 'most', 'of', 'his', 'fans', 'would', 'say', 'that', 'he', 'made', 'it', 'for', 'the', 'fans', 'which', 'if', 'true', 'is', 'really', 'nice', 'of', 'him', 'the', 'actual', 'feature', 'film', 'bit', 'when', 'it', 'finally', 'starts', 'is', 'only', 'on', 'for', 'minutes', 'or', 'so', 'excluding', 'the', 'smooth', 'criminal', 'sequence', 'and', 'joe', 'pesci', 'is', 'convincing', 'as', 'a', 'psychopathic', 'all', 'powerful', 'drug', 'lord', 'why', 'he', 'wants', 'mj', 'dead', 'so', 'bad', 'is', 'beyond', 'me', 'because', 'mj', 'overheard', 'his', 'plans', 'nah', 'joe', 'pesci', 's', 'character', 'ranted', 'that', 'he', 'wanted', 'people', 'to', 'know', 'it', 'is', 'he', 'who', 'is', 'supplying', 'drugs', 'etc', 'so', 'i', 'dunno', 'maybe', 'he', 'just', 'hates', 'mj', 's', 'music', 'lots', 'of', 'cool', 'things', 'in', 'this', 'like', 'mj', 'turning', 'into', 'a', 'car', 'and', 'a', 'robot', 'and', 'the', 'whole', 'speed', 'demon', 'sequence', 'also', 'the', 'director', 'must', 'have', 'had', 'the', 'patience', 'of', 'a', 'saint', 'when', 'it', 'came', 'to', 'filming', 'the', 'kiddy', 'bad', 'sequence', 'as', 'usually', 'directors', 'hate', 'working', 'with', 'one', 'kid', 'let', 'alone', 'a', 'whole', 'bunch', 'of', 'them', 'performing', 'a', 'complex', 'dance', 'scene', 'bottom', 'line', 'this', 'movie', 'is', 'for', 'people', 'who', 'like', 'mj', 'on', 'one', 'level', 'or', 'another', 'which', 'i', 'think', 'is', 'most', 'people', 'if', 'not', 'then', 'stay', 'away', 'it', 'does', 'try', 'and', 'give', 'off', 'a', 'wholesome', 'message', 'and', 'ironically', 'mj', 's', 'bestest', 'buddy', 'in', 'this', 'movie', 'is', 'a', 'girl', 'michael', 'jackson', 'is', 'truly', 'one', 'of', 'the', 'most', 'talented', 'people', 'ever', 'to', 'grace', 'this', 'planet', 'but', 'is', 'he', 'guilty', 'well', 'with', 'all', 'the', 'attention', 'i', 've', 'gave', 'this', 'subject', 'hmmm', 'well', 'i', 'don', 't', 'know', 'because', 'people', 'can', 'be', 'different', 'behind', 'closed', 'doors', 'i', 'know', 'this', 'for', 'a', 'fact', 'he', 'is', 'either', 'an', 'extremely', 'nice', 'but', 'stupid', 'guy', 'or', 'one', 'of', 'the', 'most', 'sickest', 'liars', 'i', 'hope', 'he', 'is', 'not', 'the', 'latter'], tags=[0])
Train Doc2Vec model - Initial pass
We are now ready to train the Doc2Vec model. The process will go something like this:
- Define the Doc2Vec model object
- Build vocabulary from a sequence of sentences (i.e. our reviews)
- Train the Doc2Vec model (Doc2Vec uses a inner shallow neural network used to train the embeddings)
- Create a feature set utilizing the trained Doc2Vec model
- Pass the feature set to the Scikit-learn models for training and evaluation
So, let’s get started!
Define the Doc2Vec model object
doc2vecModel = Doc2Vec(vector_size=50, min_count=2, epochs=40)
2018-11-08 09:49:26,290 : WARNING : consider setting layer size to a multiple of 4 for greater performance
Build vocabulary from a sequence of sentences (i.e. our reviews)
doc2vecModel.build_vocab(taggedDocs)
2018-11-08 09:49:26,739 : INFO : collecting all words and their counts
...
...
2018-11-08 09:49:27,969 : INFO : downsampling leaves estimated 4416048 word corpus (74.9% of prior 5892845)
2018-11-08 09:49:28,114 : INFO : estimated required memory for 46350 words and 50 dimensions: 46715000 bytes
2018-11-08 09:49:28,115 : INFO : resetting layer weights
Train the Doc2Vec model
doc2vecModel.train(taggedDocs, total_examples = doc2vecModel.corpus_count, epochs = doc2vecModel.epochs)
2018-11-08 09:49:29,219 : INFO : training model with 3 workers on 46350 vocabulary and 50 features, using sg=0 hs=0 sample=0.001 negative=5 window=5
2018-11-08 09:49:30,226 : INFO : EPOCH 1 - PROGRESS: at 23.21% examples, 1044966 words/s, in_qsize 5, out_qsize 0
...
...
2018-11-08 09:52:21,322 : INFO : training on a 236828520 raw words (177642503 effective words) took 172.1s, 1032204 effective words/s
A quick visual inspection of the document vector created by the model:
doc2vecModel[0]
array([-2.5997561e-01, 1.7838972e+00, -6.1637288e-01, 2.4644056e-01,
-1.2331752e+00, 5.8049954e-02, 1.7367197e+00, -5.5887252e-01,
1.6684380e+00, 7.2999865e-01, -3.6999774e+00, 5.2697855e-01,
1.2054617e+00, 1.9833222e-01, -1.1332304e-01, 2.9486263e-01,
1.2692857e+00, -1.5175811e+00, 1.7063432e+00, -3.0820298e-01,
9.1671062e-01, -5.5909568e-01, 2.7152622e-01, 3.2423854e-01,
-6.7020398e-01, -8.5734850e-01, 2.0997808e+00, -3.0700572e+00,
2.6324701e+00, 7.0944178e-01, 6.1826450e-01, -1.8692477e+00,
-1.3357389e+00, 1.2652332e-01, 1.0606683e+00, 1.5548224e+00,
-1.2767829e+00, -5.1909101e-01, 1.5628880e-03, -1.0368673e+00,
9.4668019e-01, -1.3571483e+00, -3.5316312e-01, -2.6158001e+00,
6.3104153e-01, 5.3967124e-01, -1.1993488e+00, -3.6817062e-01,
-9.6663392e-01, 4.8223326e-01], dtype=float32)
Create a feature set utilizing the trained Doc2Vec model
The docvecs property of the Doc2Vec model contains the calculated vectors for each document. Since they are numerical arrays in essence we can treat these as our training data and pass them to Scikit-learn models. Let’s do some inspections:
len(doc2vecModel.docvecs)
25000
doc2vecModel.docvecs[0]
array([-2.5997561e-01, 1.7838972e+00, -6.1637288e-01, 2.4644056e-01,
-1.2331752e+00, 5.8049954e-02, 1.7367197e+00, -5.5887252e-01,
1.6684380e+00, 7.2999865e-01, -3.6999774e+00, 5.2697855e-01,
1.2054617e+00, 1.9833222e-01, -1.1332304e-01, 2.9486263e-01,
1.2692857e+00, -1.5175811e+00, 1.7063432e+00, -3.0820298e-01,
9.1671062e-01, -5.5909568e-01, 2.7152622e-01, 3.2423854e-01,
-6.7020398e-01, -8.5734850e-01, 2.0997808e+00, -3.0700572e+00,
2.6324701e+00, 7.0944178e-01, 6.1826450e-01, -1.8692477e+00,
-1.3357389e+00, 1.2652332e-01, 1.0606683e+00, 1.5548224e+00,
-1.2767829e+00, -5.1909101e-01, 1.5628880e-03, -1.0368673e+00,
9.4668019e-01, -1.3571483e+00, -3.5316312e-01, -2.6158001e+00,
6.3104153e-01, 5.3967124e-01, -1.1993488e+00, -3.6817062e-01,
-9.6663392e-01, 4.8223326e-01], dtype=float32)
Pass the feature set to the Scikit-learn models for training and evaluation
Kaggle model
First we’ll evalute the Kaggle model. Notice how we assign the docvec values to the variable xTrain.
# Init vars and params
eFolds = 10
eSeed = 10
# Use accuracy since this is a classification problem
eScore = 'accuracy'
modelName = 'RandomForestClassifier'
RandomForestClassifier(n_estimators = 100)
xTrain = doc2vecModel.docvecs
yTrain = df.iloc[:, 1]
_DF = pd.DataFrame(columns = ['Model', 'Accuracy', 'StdDev'])
_Results = {}
_model = RandomForestClassifier(n_estimators = 100)
kFold = KFold(n_splits = eFolds, random_state = eSeed)
_Results[modelName] = cross_val_score(_model, xTrain, yTrain, cv = kFold, scoring = eScore)
_DF.loc[len(_DF)] = list(['RandomForestClassifier', _Results[modelName].mean(), _Results[modelName].std()])
display(_DF.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
| Model | Accuracy | StdDev | |
|---|---|---|---|
| 0 | RandomForestClassifier | 0.81464 | 0.008312 |
Standard write-up models
Next we’ll train the standard set of models (LR, LDA, etc.) we use in the majority of our write-ups for comparison:
results, _df = trainModels(doc2vecModel.docvecs, df.iloc[:, 1], modelsToRun = 'all')
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
Training LR ....
Training LDA ....
Training KNN ....
Training CART ....
Training NB ....
Training SVM ....
Model Accuracy StdDev
5 SVM 0.84312 0.008798
0 LR 0.83892 0.009675
1 LDA 0.83812 0.009423
4 NB 0.79136 0.008274
2 KNN 0.78140 0.011958
3 CART 0.69828 0.008404
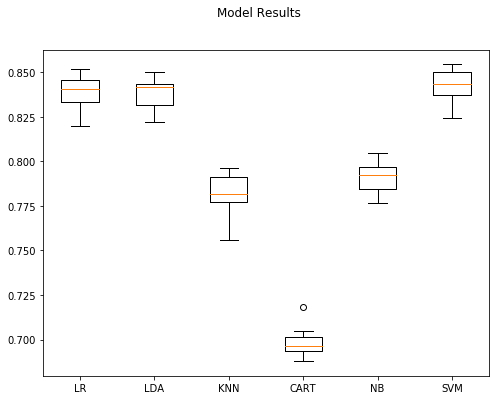
Standard model comments
The first thing I noticed right away is how much faster training the set of models was. Training wrapped up in about 9 mins compared to the sometimes hours required in previous write-ups. Accuracy was also high being only two percentage points less then the baseline model:
| Model | Accuracy | Best Params |
|---|---|---|
| LR (baseline) | 86.35% | {‘LR__C’: 0.1, ‘LR__penalty’: ‘l1’} |
| SVM centroid | 86.36% | Scikit-learn defaults |
| SVM Doc2Vec | 84.31% | Scikit-learn defaults |
Clearly for very large data sets the small drop in accuracy might be more than offset by the greatly reduced training time required.
Tuning Doc2Vec
Let’s run through the steps above again, but this time we’ll see if we can tune the Doc2Vec model and increase performance. Clearly we could spend much time on tuning parameters, and so to get a head start I pulled some initial values based on some successful recommendation found on the Internet. Two very helpful resources were:
- The original paper itself by Mikilov and Le
- Gensim’s Doc2Vec Tutorial
One note however: During my research I came across some discussion/controversy about the validity of the final accuracy score in the original paper. This also included skepticism voiced by one of the paper’s authors, Mikilov. As such we won’t try to replicate the paper’s accuracy metrics exactly, as there is some question as to whether that is possible or not on this data set.
Implementation
Create the model, build the vocab, and train
doc2vecModel = Doc2Vec(dm = 0, vector_size = 100, negative = 5, hs = 0, min_count = 2, sample = 0, epochs = 20, workers = cores)
doc2vecModel.build_vocab(taggedDocs)
doc2vecModel.train(taggedDocs, total_examples = doc2vecModel.corpus_count, epochs = doc2vecModel.epochs)
2018-11-08 10:03:27,095 : INFO : collecting all words and their counts
...
...
2018-11-08 10:04:29,193 : INFO : training on a 118414260 raw words (118356900 effective words) took 60.1s, 1970803 effective words/s
Train and assess classifiers
results, _df = trainModels(doc2vecModel.docvecs, df.iloc[:, 1], modelsToRun = 'all')
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
Training LR ....
Training LDA ....
Training KNN ....
Training CART ....
Training NB ....
Training SVM ....
Model Accuracy StdDev
5 SVM 0.88716 0.006895
0 LR 0.88460 0.006398
1 LDA 0.88448 0.006888
4 NB 0.85340 0.006517
2 KNN 0.81540 0.010377
3 CART 0.69372 0.011037
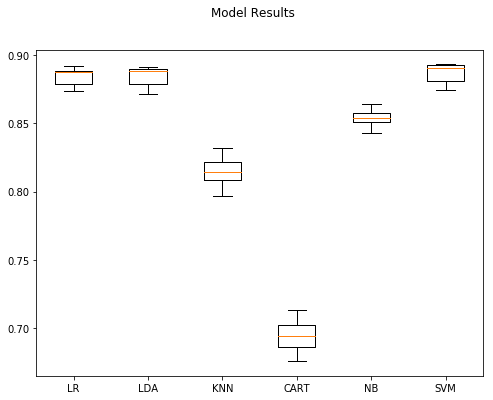
Comments
Things are clearly off to a good start with tuning. We picked up four percentage points from our first Doc2Vec model, achieved the best performing model to date, and still maintained the speed increases we enjoyed above.
Comparison table for reference:
| Model | Accuracy | Best Params |
|---|---|---|
| LR (baseline) | 86.35% | {‘LR__C’: 0.1, ‘LR__penalty’: ‘l1’} |
| SVM centroid | 86.36% | Scikit-learn defaults |
| SVM Doc2Vec | 84.48% | Scikit-learn defaults |
| SVM Doc2Vec Init tuning | 88.71% | dm0, vs100, ng5, hs0, mc2, sm0, e20 |
Combining Doc2Vec models
Another method we can explore is combining the outputs of two Doc2Vec models similar to an pseudo-ensemble. This can be done by using np.hstack to concatenate the document vectors from the two (or more) models. The output will be one combined vector per review, and this can be fed into the Scikit-lern evaluations as the feature set.
Let’s create three Doc2Vec models, train them, make a few feature set combinations, and see if we realize any improvement in accuracy:
Create Doc2Vec models, build vocabulary, and train
# Instantiate each model
m1 = Doc2Vec(dm=1, dm_concat=1, size=100, window=5, negative=5, hs=0, min_count=2, workers=cores)
m2 = Doc2Vec(dm=0, size=100, negative=5, hs=0, min_count=2, workers=cores)
m3 = Doc2Vec(dm=1, dm_mean=1, size=100, window=10, negative=5, hs=0, min_count=2, workers=cores)
# Build vocab with first model
m1.build_vocab(taggedDocs)
# Share first model's vocab scan w/ the other models
m2.reset_from(m1)
m3.reset_from(m1)
# Model training params
alpha, min_alpha, passes = (0.025, 0.001, 20)
# Train each model on the labeled training data
m1.train(taggedDocs, total_examples = m1.corpus_count, start_alpha = alpha, end_alpha = min_alpha, epochs = passes)
m2.train(taggedDocs, total_examples = m2.corpus_count, start_alpha = alpha, end_alpha = min_alpha, epochs = passes)
m3.train(taggedDocs, total_examples = m3.corpus_count, start_alpha = alpha, end_alpha = min_alpha, epochs = passes)
2018-11-08 10:13:43,506 : INFO : using concatenative 1100-dimensional layer1
2018-11-08 10:13:43,506 : INFO : collecting all words and their counts
...
...
2018-11-08 10:18:46,079 : INFO : training on a 118414260 raw words (88818221 effective words) took 80.2s, 1107880 effective words/s
Combination one: Train and assess classifiers
Notice below how we iterate through the document vectors from both models and combine them with np.hstack.
# Build the feature set by combining vectors from multiple models (m1 and m2)
xTrain = []
for i in range(0, len(taggedDocs)):
xTrain.append(np.hstack((m1.docvecs[i], m2.docvecs[i])))
print("len(xTrain)", len(xTrain))
results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['SVM', 'LDA', 'LR'])
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
len(xTrain) 25000
Training LR ....
Training LDA ....
Training SVM ....
Model Accuracy StdDev
0 LR 0.88624 0.007783
1 LDA 0.88556 0.005966
2 SVM 0.88464 0.008174
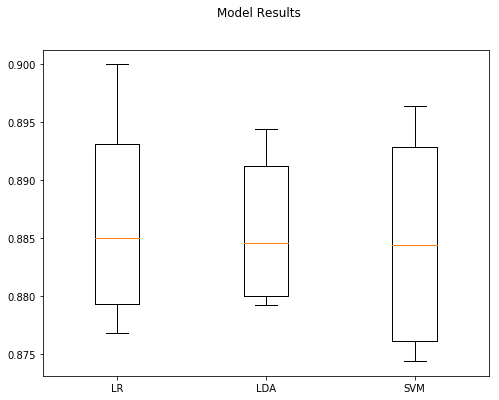
Combination two: Train and assess classifiers
# Build the feature set by combining vectors from multiple models (m2 and m3)
xTrain = []
for i in range(0, len(taggedDocs)):
xTrain.append(np.hstack((m2.docvecs[i], m3.docvecs[i])))
print("len(xTrain)", len(xTrain))
results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['SVM', 'LDA', 'LR'])
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
len(xTrain) 25000
Training LR ....
Training LDA ....
Training SVM ....
Model Accuracy StdDev
2 SVM 0.88676 0.006982
1 LDA 0.88548 0.006833
0 LR 0.88536 0.007341
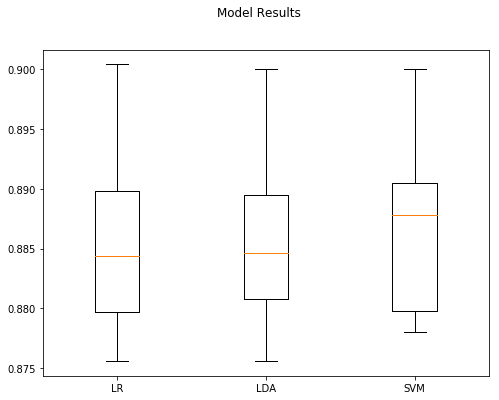
Comments
We actually dropped a tiny amount in of accuracy from the previous section although it doesn’t appear to be statistically significant. Let’s try again, but now we’ll expand the corpus the models have access to.
Increased vocabulary and combined Doc2Vec models
What if we increase the size of the vocabulary the Doc2Vec model has access to? In order to do this we’ll feed all the review text we have–labeled and unlabeled–into the model’s and then train and evaluate as before:
Process and combine unlabeled data
# Pull in the unlabeled data since it can also be utilized by Doc2Vec when building the vocab
unlabeledTrainData = os.path.join(dataPath, 'unlabeledTrainData.tsv')
dfUn = pd.read_csv(unlabeledTrainData, sep = '\t', header = 0, quoting = 3)
# Create an all document object we can pass to the models
allDocs = taggedDocs.copy()
for s in dfUn.iloc[:,1]:
clean = cleanReview(s)
i = len(allDocs)
allDocs.append(TaggedDocument(clean, [i]))
len(allDocs)
75000
Create Doc2Vec models, build vocabulary, and train
# Instantiate each model
m1 = Doc2Vec(dm=1, dm_concat=1, size=100, window=5, negative=5, hs=0, min_count=2, workers=cores)
m2 = Doc2Vec(dm=0, size=100, negative=5, hs=0, min_count=2, workers=cores)
m3 = Doc2Vec(dm=1, dm_mean=1, size=100, window=10, negative=5, hs=0, min_count=2, workers=cores)
# Build vocab with first model using all documents
m1.build_vocab(allDocs)
# Share first model's vocab scan w/ the other models
m2.reset_from(m1)
m3.reset_from(m1)
# Model training params
alpha, min_alpha, passes = (0.025, 0.001, 20)
# Train each model on the labeled training data
m1.train(taggedDocs, total_examples = m1.corpus_count, start_alpha = alpha, end_alpha = min_alpha, epochs = passes)
m2.train(taggedDocs, total_examples = m2.corpus_count, start_alpha = alpha, end_alpha = min_alpha, epochs = passes)
m3.train(taggedDocs, total_examples = m3.corpus_count, start_alpha = alpha, end_alpha = min_alpha, epochs = passes)
2018-11-08 10:43:22,058 : INFO : using concatenative 1100-dimensional layer1
2018-11-08 10:43:22,105 : INFO : collecting all words and their counts
...
...
2018-11-08 10:48:51,944 : INFO : training on a 118414260 raw words (89085416 effective words) took 85.9s, 1037253 effective words/s
Combination one: Train and assess classifiers
# Build the feature set by combining vectors from multiple models (m1 and m2)
xTrain = []
for i in range(0, len(taggedDocs)):
xTrain.append(np.hstack((m1.docvecs[i], m2.docvecs[i])))
print("len(xTrain)", len(xTrain))
results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['SVM', 'LDA', 'LR'])
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
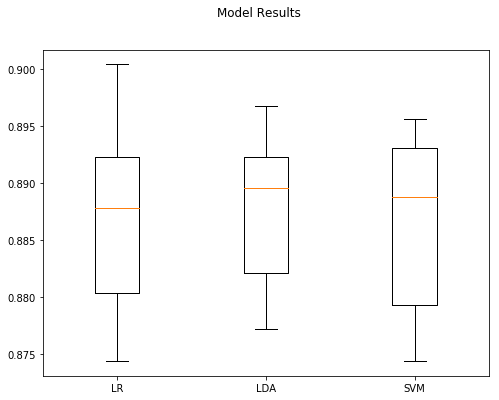
len(xTrain) 25000
Training LR ....
Training LDA ....
Training SVM ....
Model Accuracy StdDev
1 LDA 0.88760 0.006350
0 LR 0.88688 0.007797
2 SVM 0.88684 0.007620
Combination Two: Train and assess classifiers
# Build the feature set by combining vectors from multiple models (m2 and m3)
xTrain = []
for i in tqdm(range(0, len(taggedDocs))):
xTrain.append(np.hstack((m2.docvecs[i], m3.docvecs[i])))
print("len(xTrain)", len(xTrain))
results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['SVM', 'LDA', 'LR'])
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
100%|██████████| 25000/25000 [00:00<00:00, 147061.23it/s]
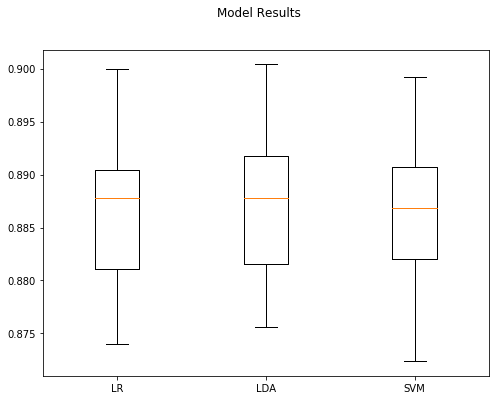
len(xTrain) 25000
Training LR ....
Training LDA ....
Training SVM ....
Model Accuracy StdDev
1 LDA 0.88708 0.007432
0 LR 0.88632 0.007589
2 SVM 0.88556 0.007856
Comments
We picked up less than a full percentage point of accuracy, so it doesn’t appear this method provides meaningful gains to the classification task at hand. Let’s continue and try another implementation strategy:
Manual training and feature set creation utilizing combined Doc2Vec models
Next we’ll try the same three Doc2Vec models we utilized before with a vocabulary created from the full suite of review text. The training process will be implemented manually, we’ll adjust the alpha value it epoch, and we’ll train the models on the entire review corpus. Once this is done we’ll utilize the infer_vector method of the models to manually create the labeled document vectors (i.e. our feature set), since the docvecs property will now contain a mix of labeled and un-labeled document vectors.
Create Doc2Vec models, build vocabulary, and train
# Instantiate each model
m1 = Doc2Vec(dm=1, dm_concat=1, size=100, window=5, negative=5, hs=0, min_count=2, workers=cores)
m2 = Doc2Vec(dm=0, size=100, negative=5, hs=0, min_count=2, workers=cores)
m3 = Doc2Vec(dm=1, dm_mean=1, size=100, window=10, negative=5, hs=0, min_count=2, workers=cores)
# Build vocab with first model using all documents
m1.build_vocab(allDocs)
# Share first model's vocab scan w/ the other models
m2.reset_from(m1)
m3.reset_from(m1)
# Set training params
alpha, min_alpha, passes = (0.025, 0.001, 20)
alpha_delta = (alpha - min_alpha) / passes
# Train the models
for epoch in range(passes):
# Shuffle the documents; literature reports this provides the best results
shuffle(allDocs)
# Train the models
m1.alpha, m1.min_alpha = alpha, alpha
m1.train(allDocs, total_examples = m1.corpus_count, epochs = 1)
m2.alpha, m2.min_alpha = alpha, alpha
m2.train(allDocs, total_examples = m2.corpus_count, epochs = 1)
m3.alpha, m3.min_alpha = alpha, alpha
m3.train(allDocs, total_examples = m3.corpus_count, epochs = 1)
alpha -= alpha_delta
2018-11-08 11:10:54,023 : INFO : using concatenative 1100-dimensional layer1
2018-11-08 11:10:54,117 : INFO : collecting all words and their counts
...
...
2018-11-08 11:26:51,837 : INFO : training on a 17797887 raw words (13393076 effective words) took 15.9s, 842125 effective words/s
Combination one: Train and assess classifiers
# Build the feature set by combining vectors from multiple models (m2 and m3)
xTrain = []
infer_steps = 5
infer_alpha = 0.01
for i in tqdm(range(0, len(taggedDocs))):
xTrain.append(np.hstack((
m1.infer_vector(taggedDocs[i].words, steps=infer_steps, alpha=infer_alpha),
m2.infer_vector(taggedDocs[i].words, steps=infer_steps, alpha=infer_alpha)
)))
print("len(xTrain)", len(xTrain))
100%|██████████| 25000/25000 [02:11<00:00, 190.22it/s]
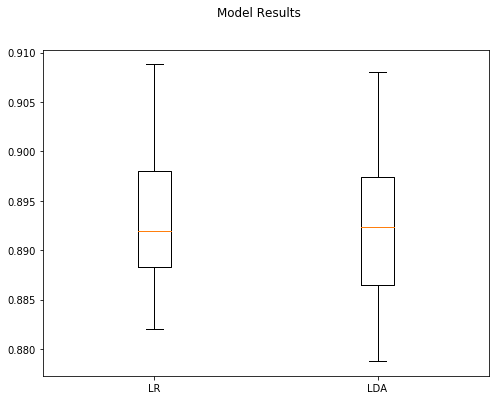
len(xTrain) 25000
#results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['SVM', 'LDA', 'LR'])
results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['LDA', 'LR'])
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
Training LR ....
Training LDA ....
Model Accuracy StdDev
0 LR 0.89372 0.007636
1 LDA 0.89248 0.008152
Combination two: Train and assess classifiers
# Build the feature set by combining vectors from multiple models (m2 and m3)
xTrain = []
infer_steps = 7
infer_alpha = 0.01
for i in tqdm(range(0, len(taggedDocs))):
xTrain.append(np.hstack((
m1.infer_vector(taggedDocs[i].words, steps=infer_steps, alpha=infer_alpha),
m2.infer_vector(taggedDocs[i].words, steps=infer_steps, alpha=infer_alpha),
m3.infer_vector(taggedDocs[i].words, steps=infer_steps, alpha=infer_alpha)
)))
print("len(xTrain)", len(xTrain))
100%|██████████| 25000/25000 [03:55<00:00, 106.05it/s]
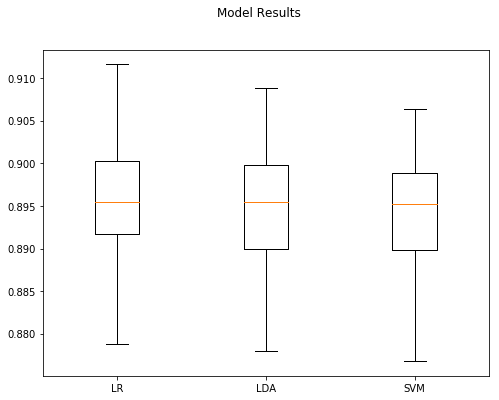
len(xTrain) 25000
results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['SVM', 'LDA', 'LR'])
#results, _df = trainModels(xTrain, df.iloc[:, 1], modelsToRun = ['LDA', 'LR'])
print(_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
makeWhisker(results)
Training LR ....
Training LDA ....
Training SVM ....
Model Accuracy StdDev
0 LR 0.89512 0.008924
1 LDA 0.89384 0.008921
2 SVM 0.89352 0.008623
Comments
So far Doc2Vec with combined models and manual training has given us the best results with a 89.51% on the training data. This is 3 percentage points over the baseline and the Doc2Vec centroid models, and 5 percentage points better than the initial, untuned Doc2Ved model.
Summary
In this write-up we accomplished the following:
- Created a set of document vectors from the IMDb movie review text utilizing Doc2Vec
- Tuned and trained a number of Doc2Vec models on the movie review corpus
- Ran the models from the first write-up against the Doc2Vec feature set outputs
- Evaluated if utilizing Doc2Vec improved our ability to correctly classify movie review sentiment
Performance metrics so far:
| Model | Accuracy | Best Params |
|---|---|---|
| LR (baseline) | 86.35% | {‘LR__C’: 0.1, ‘LR__penalty’: ‘l1’} |
| SVM centroid | 86.36% | Scikit-learn defaults |
| SVM Doc2Vec | 84.48% | Scikit-learn defaults |
| SVM Doc2Vec Init tuning | 88.45% | dm0, vs100, ng5, hs0, mc2, sm0, e20 |
| LR manual/combined | 89.51% | model1, model2, model3 |
Utilizing Doc2Vec with manual training and combining model outputs has given us the best classification results to date. We were able to gain over 3 percentage points in performance from the LR baseline model.
If we were to continue this write-up it would be interesting to explore adding many models together and seeing how that affected the output similar to bagging. We could also likely spend a lot of time with further tuning, because both the Doc2Vec and Scikit-learn models have a large number of tunable parameters we could leverage. The best strategy would likely be to start with a randomized grid search due to the large number of parameters, and then focus in on a more narrow set once the more performant combinations started to emerge.
And lastly, I’d also like to try taking the combined model feature set and feeding it to a neural network or LSTM for final classification. It would be interesting to see how one of these more complex algorithms compared against the Scikit-learn linear regression model.
You can find the source Jupyter Notebook on GitHub here.



Comments