
The overall goal of this series is to explore a number of machine learning algorithms utilizing natural language processing (NLP) to classify the sentiment in a set of IMDB movie reviews.
The specific goals of this particular post include:
- Create a set of word embeddings from the IMDb movie review text utilizing Word2vec
- Cluster the embeddings utilizing a K-nearest neighbors algorithm into a set of centroids
- Run the models from the first write-up against the centroid feature set
- Determine if the centroid feature set improves our ability to correctly classify movie review sentiment
Links
- This series of write-ups is inspired by the Kaggle Bag of Words Meets Bags of Popcorn competition.
- Dataset source: IMDB Movie Reviews
- You can find the source Jupyter Notebook on GitHub here.
Previous
Previous entries in this series:
- IMDB Movie Review Sentiment Classification - Part One
- Creating the baseline model
- IMDB Movie Review Sentiment Classification - Part Two
- Utilizing a sparse feature set
Process
Previously covered here.
Configure notebook, import libraries, and import dataset
Import libraries
%matplotlib inline
%load_ext autoreload
%autoreload 2
import warnings
warnings.filterwarnings('ignore')
import os
import re
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from pandas import set_option
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.pipeline import Pipeline
from sklearn.pipeline import FeatureUnion
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.cluster import KMeans
# http://www.nltk.org/index.html
# pip install nltk
import nltk
from nltk.corpus import stopwords
# Creating function implementing punkt tokenizer for sentence splitting
import nltk.data
# Only need this the first time...
# nltk.download('punkt')
# https://www.crummy.com/software/BeautifulSoup/bs4/doc/
# pip install BeautifulSoup4
from bs4 import BeautifulSoup
# https://pypi.org/project/gensim/
# pip install gensim
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level = logging.INFO)
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Define global variables
seed = 10
np.random.seed(seed)
# Opens a GUI that allows us to download the NLTK data
# nltk.download()
dataPath = os.path.join('.', 'datasets', 'imdb_movie_reviews')
labeledTrainData = os.path.join(dataPath, 'labeledTrainData.tsv')
Import labeled data
df = pd.read_csv(labeledTrainData, sep = '\t', header = 0, quoting = 3)
Examine the data
Previously covered here.
Cleaning and preprocessing
Load training data
(Previous process justification and methodology also previously covered here.)
First, read in the labeled training data (which we’ve done before) as well as the unlabeled training data (which is new to this write-up). The more data we can feed to Word2Vec the better, and this will help the algorithm associate related words more accurately.
# Pull in the labeled data
labeledTrainData = os.path.join(dataPath, 'labeledTrainData.tsv')
df = pd.read_csv(labeledTrainData, sep = '\t', header = 0, quoting = 3)
# Pull in the unlabeled data since it can also be utilized by Word2Vec
unlabeledTrainData = os.path.join(dataPath, 'unlabeledTrainData.tsv')
dfUn = pd.read_csv(unlabeledTrainData, sep = '\t', header = 0, quoting = 3)
# Validation
print('df.shape :', df.shape)
print('dfUn.shape :', dfUn.shape)
df.shape : (25000, 3)
dfUn.shape : (50000, 2)
Write helper functions
Word2Vec expects single sentences as inputs, and each sentence formatted as a list of words (i.e. a list of lists). Let’s write two functions to achieve this next.
Sentence cleaner
Take a given sentence and process/clean it (i.e. remove HTML and other cruft, lower case the text, etc.).
# Update stop word helper function to output a list of words
# Clean IMDB review text
def cleanReview(review, removeStopWords = False):
# Convert the stop words to a set
stopWords = set(stopwords.words("english"))
# Remove HTML
clean = BeautifulSoup(review)
# Remove non-alpha chars
clean = re.sub("[^a-zA-Z]", ' ', clean.get_text())
# Convert to lower case and "tokenize"
clean = clean.lower().split()
# Remove stop words
if removeStopWords:
clean = [x for x in clean if not x in stopWords]
# Return results
return clean
A quick examination of the output:
# Examine
cleanReview(df.iloc[25,2])[:12]
['looking',
'for',
'quo',
'vadis',
'at',
'my',
'local',
'video',
'store',
'i',
'found',
'this']
# Examine
cleanReview(dfUn.iloc[0,1])[:12]
['watching',
'time',
'chasers',
'it',
'obvious',
'that',
'it',
'was',
'made',
'by',
'a',
'bunch']
Review tokenizer
Given a blob of review text tokenize it into individual sentences, and then feed those sentences to the sentence cleaner function for processing. The final output should be a list of lists suitable for use by Word2Vec.
# Load the punkt tokenizer
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
# Define a function to split a review into parsed sentences
def createSentences(review, tokenizer, remove_stopwords = False):
# Init container to hold results
sentences = []
# Split review string into sentences
tokenSentences = tokenizer.tokenize(review.strip())
# Clean the sentences via cleanReview() function
for s in tokenSentences:
# If a sentence is empty, skip it
if len(s) > 0:
# Clean sentence
sentences.append( cleanReview( s, remove_stopwords ))
# Return list of clean sentences
return sentences
A quick examination of the output:
# Examine
_ = createSentences(df.iloc[25,2], tokenizer)
print(_[0][:12])
print(len(_))
['looking', 'for', 'quo', 'vadis', 'at', 'my', 'local', 'video', 'store', 'i', 'found', 'this']
8
# Examine
_ = createSentences(dfUn.iloc[0,1], tokenizer)
print(_[0][:12])
print(len(_))
['watching', 'time', 'chasers', 'it', 'obvious', 'that', 'it', 'was', 'made', 'by', 'a', 'bunch']
5
Process training data
Now we’ll combine the labeled and unlabeled training data and output the list of lists utilizing the helper functions we wrote above:
combined = []
for s in df.iloc[:,2]:
combined += createSentences(s, tokenizer)
for s in dfUn.iloc[:,1]:
combined += createSentences(s, tokenizer)
Quick examination:
print('len(combined): ', len(combined))
print("\nSample sentence:")
print(combined[0])
len(combined): 795538
Sample sentence:
['with', 'all', 'this', 'stuff', 'going', 'down', 'at', 'the', 'moment', 'with', 'mj', 'i', 've', 'started', 'listening', 'to', 'his', 'music', 'watching', 'the', 'odd', 'documentary', 'here', 'and', 'there', 'watched', 'the', 'wiz', 'and', 'watched', 'moonwalker', 'again']
Train Word2Vec
Train the Word2Vec model on the processed training data (labled and unlabeled) from the previous steps:
# Set Word2Vec params
features = 300 # Word vector dimensionality
minWordCount = 40 # Minimum word count
workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
downSampling = 1e-3 # Downsample setting for frequent words
model = word2vec.Word2Vec(combined,
workers=workers,
size=features,
min_count = minWordCount,
window = context,
sample = downSampling)
# https://tedboy.github.io/nlps/generated/generated/gensim.models.Word2Vec.init_sims.html
# If replace is set, forget the original vectors and only keep the normalized ones = saves lots of memory!
# Note that you cannot continue training after doing a replace.
# The model becomes effectively read-only = you can call most_similar, similarity etc., but not train.
model.init_sims(replace = True)
# Save model to disk
model.save("300features_40minwords_10context")
2018-11-01 14:34:28,272 : INFO : collecting all words and their counts
2018-11-01 14:34:28,272 : INFO : PROGRESS: at sentence #0, processed 0 words, keeping 0 word types
2018-11-01 14:34:28,315 : INFO : PROGRESS: at sentence #10000, processed 225803 words, keeping 17776 word types
2018-11-01 14:34:31,850 : INFO : PROGRESS: at sentence #790000, processed 17674981 words, keeping 123066 word types
...
2018-11-01 14:34:31,874 : INFO : collected 123504 word types from a corpus of 17798082 raw words and 795538 sentences
2018-11-01 14:34:31,875 : INFO : Loading a fresh vocabulary
2018-11-01 14:34:31,944 : INFO : effective_min_count=40 retains 16490 unique words (13% of original 123504, drops 107014)
2018-11-01 14:34:31,945 : INFO : effective_min_count=40 leaves 17238940 word corpus (96% of original 17798082, drops 559142)
2018-11-01 14:34:31,989 : INFO : deleting the raw counts dictionary of 123504 items
2018-11-01 14:34:31,992 : INFO : sample=0.001 downsamples 48 most-common words
2018-11-01 14:34:31,993 : INFO : downsampling leaves estimated 12749658 word corpus (74.0% of prior 17238940)
2018-11-01 14:34:32,042 : INFO : estimated required memory for 16490 words and 300 dimensions: 47821000 bytes
2018-11-01 14:34:32,043 : INFO : resetting layer weights
2018-11-01 14:34:32,253 : INFO : training model with 4 workers on 16490 vocabulary and 300 features, using sg=0 hs=0 sample=0.001 negative=5 window=10
2018-11-01 14:34:33,265 : INFO : EPOCH 1 - PROGRESS: at 7.30% examples, 925694 words/s, in_qsize 7, out_qsize 2
2018-11-01 14:34:34,279 : INFO : EPOCH 1 - PROGRESS: at 15.50% examples, 975033 words/s, in_qsize 7, out_qsize 1
2018-11-01 14:34:35,283 : INFO : EPOCH 1 - PROGRESS: at 23.60% examples, 989478 words/s, in_qsize 7, out_qsize 1
2018-11-01 14:35:48,015 : INFO : EPOCH 5 - PROGRESS: at 96.13% examples, 863652 words/s, in_qsize 8, out_qsize 2
...
2018-11-01 14:35:48,531 : INFO : worker thread finished; awaiting finish of 3 more threads
2018-11-01 14:35:48,537 : INFO : worker thread finished; awaiting finish of 2 more threads
2018-11-01 14:35:48,549 : INFO : worker thread finished; awaiting finish of 1 more threads
2018-11-01 14:35:48,550 : INFO : worker thread finished; awaiting finish of 0 more threads
2018-11-01 14:35:48,550 : INFO : EPOCH - 5 : training on 17798082 raw words (12749443 effective words) took 14.7s, 866196 effective words/s
2018-11-01 14:35:48,551 : INFO : training on a 88990410 raw words (63745812 effective words) took 76.3s, 835511 effective words/s
2018-11-01 14:35:48,551 : INFO : precomputing L2-norms of word weight vectors
2018-11-01 14:35:48,676 : INFO : saving Word2Vec object under 300features_40minwords_10context, separately None
2018-11-01 14:35:48,677 : INFO : not storing attribute vectors_norm
2018-11-01 14:35:48,678 : INFO : not storing attribute cum_table
2018-11-01 14:35:49,300 : INFO : saved 300features_40minwords_10context
Explore the results:
model.most_similar("great")
[('terrific', 0.730087399482727),
('fantastic', 0.7199629545211792),
('wonderful', 0.7167843580245972),
('superb', 0.6425317525863647),
('fine', 0.6420440673828125),
('brilliant', 0.6286628246307373),
('marvelous', 0.6202216148376465),
('excellent', 0.6188085079193115),
('good', 0.6166402101516724),
('amazing', 0.5603896975517273)]
model.most_similar("awful")
[('terrible', 0.777208149433136),
('horrible', 0.7345371246337891),
('abysmal', 0.7309399247169495),
('atrocious', 0.7255470156669617),
('dreadful', 0.7129322290420532),
('horrendous', 0.6862552165985107),
('horrid', 0.6757344007492065),
('appalling', 0.6731106042861938),
('amateurish', 0.632673978805542),
('lousy', 0.6291776895523071)]
One of the reviews we referred to often in previous write-ups was a zombie movie, so let’s see what words are similar/associated with the word ‘zombie’:
model.most_similar("zombie")
[('cannibal', 0.6610051393508911),
('slasher', 0.6199641227722168),
('horror', 0.6184082627296448),
('zombies', 0.613161027431488),
('monster', 0.6093231439590454),
('vampire', 0.6016378402709961),
('fulci', 0.5893048048019409),
('splatter', 0.5890129804611206),
('werewolf', 0.5860388278961182),
('chainsaw', 0.5515424013137817)]
That looks pretty good!
Note that Fulci is the name of a movie director renowned for zombie movies, which I think is actually the most interesting result of the associations and really show the power of the algorithm….
And we’ll finish off with a quick check of how many words had vectors created:
len(model.wv.index2word)
16490
Centroid development
Now that we have a trained Word2Vec model with some semantic understanding of words, how should we use it?
We’ll try clustering (i.e. centroids)–even though according to Kaggle it doesn’t offer an improvement–as a programming exercise before moving on to other methods.
Note that the Word2Vec model we trained consists of a feature vector for each word in the vocabulary. The feature vectors can be accessed via the “syn0” object property.
# Set "k" to be 1/5th of the vocabulary size, or an average of 5 words per cluster
wordVecs = model.wv.syn0
k = int(wordVecs.shape[0] / 5)
# Initalize a k-means object and use it to extract centroids
kMeans = KMeans( n_clusters = k )
kModel = kMeans.fit_predict(wordVecs)
So now we have K clusters, and each word in the Word2Vec vocabulary has been assigned to one of the clusters. Next we want to combine the actual words with their cluster assignments. We can pull the words themselves from the Word2Vec object with the following property:
model.wv.index2word
Let’s ensure the list lengths match and then combine the words and their assignments into a dictionary object:
print(len(model.wv.index2word))
print(len(kModel))
print(model.wv.index2word[:5])
print(kModel[:5])
16490
16490
['the', 'and', 'a', 'of', 'to']
[2546 171 2750 2445 2349]
clusterDict = dict(zip(model.wv.index2word, kModel))
Quick visual inspection:
for i, k in enumerate(clusterDict.keys()):
print(k, "=", clusterDict[k])
if i > 3:
break
the = 2546
and = 171
a = 2750
of = 2445
to = 2349
# Examine the first 10 clusters
for cluster in range(0,10):
#
# Print the cluster number
print("\nCluster %d" % cluster)
#
# Find all of the words for that cluster number, and print them out
words = []
for i in range(0,len(clusterDict.values())):
if( list(clusterDict.values())[i] == cluster ):
words.append(list(clusterDict.keys())[i])
print(words)
Cluster 0
['courtroom', 'pivotal', 'stealer']
Cluster 1
['francis', 'fleming', 'diaz', 'crane', 'cristina', 'regal', 'rhonda', 'reyes', 'petulia']
Cluster 2
['charged', 'cunning', 'cerebral', 'elusive', 'evolving', 'heated', 'volatile', 'comforting', 'guiding', 'shamefully', 'smarts']
Cluster 3
['underwear', 'cleavage', 'panties', 'baring', 'strut']
Cluster 4
['ancient', 'underground', 'forbidden', 'egyptian', 'occult', 'mythological', 'aztec', 'kells']
Cluster 5
['repetitive', 'tiresome', 'monotonous', 'tiring']
Cluster 6
['bang', 'stairs', 'scratch', 'climbing', 'pin', 'climb', 'ladder']
Cluster 7
['association']
Cluster 8
['madness', 'menace', 'paranoia', 'relentless', 'izo', 'increases', 'decay', 'deceit', 'treachery', 'intrigues']
Cluster 9
['creepy', 'effective', 'stylish', 'atmospheric', 'eerie', 'spooky', 'gothic', 'moody', 'claustrophobic', 'ominous', 'unnerving']
Feature array creation
Previously when we implemented bag-of-words we counted up how many times a certain word appeared in each review. We were hoping that word count patterns would emerge in similar reviews, and that would help us classify unseen reviews as good or bad by comparing their word count patterns.
In this instance we are doing the same thing, but instead of counting word occurrences we are counting how many times the cluster containing a given word appears in the review. Again, we are hoping that cluster count patterns emerge that are similar between like reviews, and that we can use this to identify unseen reviews as good or bad. We are switching from individual words to semantically related cluster comparisons.
The first thing we need to do is write a function that returns a an array for a given review. Each entry in the array should correspond to a cluster in our set, and the values for the array entries will the number of times the cluster was found in the review text. The output of this work will be the feature set we feed to the models for training.
Write helper function
def createFeatureArray(sentences, clusterDict):
# Init result array to return
results = np.zeros(centroids, dtype="float32")
# The number of clusters is equal to the highest cluster index in the word / centroid map
centroids = max(clusterDict.values()) + 1
# Loop over review word(s) and count which cluster it belonged to
for sentence in sentences:
for word in sentence:
# Check if the word is in our vocabulary, if so increment its cluster
if word in clusterDict:
index = clusterDict[word]
results[index] += 1
# Return centroid counts
return results
Tokenize and clean labeled training data
trainSentences = []
for s in df.iloc[:,2]:
trainSentences.append(createSentences(s, tokenizer, remove_stopwords = True))
Create feature set centroids
We’ll take the output from above and create the centroid feature set to pass to the models for training
k = int(wordVecs.shape[0] / 5)
# Init training variable
xTrain = np.zeros( (df.iloc[:,2].size, k), dtype="float32")
# Transform the training set reviews into bags of centroids
counter = 0
for review in trainSentences:
xTrain[counter,:] = createFeatureArray(review, clusterDict)
counter += 1
Classification model training and evaluation
Kaggle model
First we’ll evalute the Kaggle model:
# Init vars and params
eFolds = 10
eSeed = 10
# Use accuracy since this is a classification problem
eScore = 'accuracy'
modelName = 'RandomForestClassifier'
RandomForestClassifier(n_estimators = 100)
yTrain = df.iloc[:, 1]
_DF = pd.DataFrame(columns = ['Model', 'Accuracy', 'StdDev'])
_Results = {}
_model = RandomForestClassifier(n_estimators = 100)
kFold = KFold(n_splits = eFolds, random_state = eSeed)
_Results[modelName] = cross_val_score(_model, xTrain, yTrain, cv = kFold, scoring = eScore)
_DF.loc[len(_DF)] = list(['RandomForestClassifier', _Results[modelName].mean(), _Results[modelName].std()])
display(_DF.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True]))
| Model | Accuracy | StdDev | |
|---|---|---|---|
| 0 | RandomForestClassifier | 0.8468 | 0.008575 |
This is 2% less accurate then the baseline.
Standard write-up models
Next we’ll train the standard set of models (LR, LDA, etc.) we use in the majority of our write-ups for comparison:
# Init vars
folds = 10
seed = 10
models = []
results = {}
# Use accuracy since this is a classification
score = 'accuracy'
# Instantiate model objects
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# Create a Pandas DF to hold all our spiffy results
_df = pd.DataFrame(columns = ['Model', 'Accuracy', 'StdDev'])
# Run the models
for modelName, model in models:
print("Training", modelName, "....")
# Implement K-fold cross validation where K = 10
kFold = KFold(n_splits = folds, random_state = seed)
results[modelName] = cross_val_score(model, xTrain, yTrain, cv = kFold, scoring = score)
_df.loc[len(_df)] = list([modelName, results[modelName].mean(), results[modelName].std()])
# Print results sorted by Mean desc, StdDev asc, Model asc
_df.sort_values(by = ['Accuracy', 'StdDev', 'Model'], ascending = [False, True, True])
Training LR ....
Training LDA ....
Training KNN ....
Training CART ....
Training NB ....
Training SVM ....
| Model | Accuracy | StdDev | |
|---|---|---|---|
| 5 | SVM | 0.86360 | 0.007302 |
| 0 | LR | 0.86116 | 0.007448 |
| 1 | LDA | 0.84468 | 0.007135 |
| 3 | CART | 0.72948 | 0.007321 |
| 4 | NB | 0.72268 | 0.007147 |
| 2 | KNN | 0.70520 | 0.010916 |
figure = plt.figure(figsize = (8,6))
figure.suptitle("Model Results")
axis = figure.add_subplot(111)
plt.boxplot(results.values())
axis.set_xticklabels(results.keys())
plt.show()
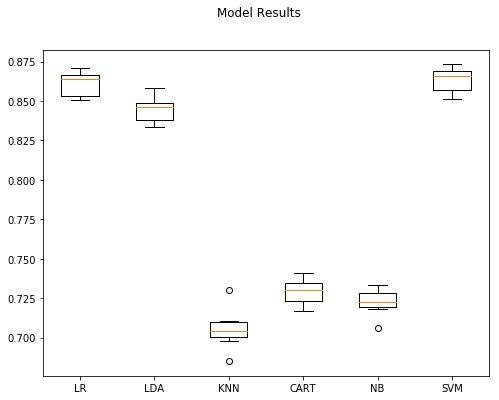
LR, LDA, and SVM were the clear winners here with SVM and LR kneck-in-kneck for top performance. Both had high accuracy and lower standard deviations.
Summary
In this write-up we accomplished the following:
- Created a set of word embeddings from the IMDb movie review text utilizing Word2vec
- Clustered the embeddings utilizing a K-nearest neighbors algorithm into a set of centroids
- Trained and evaluated the models from the last write-up against the centroid feature set
And finally, here is the baseline model’s performance vs. the ‘centroid’ model we developed in this write-up:
| Model | Accuracy | Best Params |
|---|---|---|
| LR (baseline) | 86.35% | {‘LR__C’: 0.1, ‘LR__penalty’: ‘l1’} |
| Kaggle centroid | 84.68% | Estimators = 100 |
| SVM centroid | 86.36% | Scikit-learn defaults |
Similar to the last last write-up the work in this notebook was an interesting idea to explore, but ultimately didn’t result in an overall performance increase versus the baseline model. As such this line of exploration will be rejected in favor of keeping the current base line model and accuracy rating as benchmarks moving forward.
You can find the source Jupyter Notebook on GitHub here.


Comments